
I programmi di riconoscimento ottico dei caratteri (Ocr) consentono, dopo aver acquisito i documenti tramite scanner, di convertrli in formato testuale, come se fossero stati scritti tramite word processor. Questa categoria di software offre oggi risultati stupefacenti ma rimangono pacchetti in genere commerciali e non economici.
Nel mondo freeware e open source ci sono due progetti che seppur non dotati delle ricche funzioni disponibili nelle soluzioni commerciali, offrono risultati molto apprezzabili, a patto che la qualità della scansione sia buona (almeno 300dpi ma anche risoluzioni maggiori se il documento presenta caratteri particolarmente piccoli ) e che si sia disposti ad indicare la struttura del documento manualmente qualora questa sia complessa (quindi per i documenti che hanno testo disposto su più colonne, immagini, tabelle e cosi via).
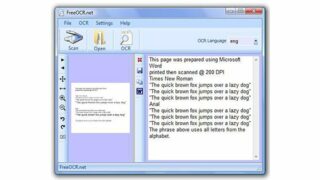
FreeOCR è un progetto che impiega il motore open source Tesseract che è stato originariamente sviluppato da HP e poi acquistato da Google. Il programma, oltre ad essere in grado di analizzare le immagini Tiff, può processare direttamente file in formto Pdf .
FreeOCR è in grado di elaborare documenti in numerose lingue. Di base offre l’italiano, l’inglese, il danese, il tedesco, il francese, lo spagnolo, il polacco, lo svedese, il norvegese, l’olandese e il finnico.
Il programma consente di riconoscere solo il testo: eventuali formattazioni del documento originale saranno quindi perse anche se utilizziamo il pulsante di esportazione verso Word. Inoltre non supporta testo disposto in colonne multiple: in questi casi è necessario indicare manualmente di analizzare una colonna alla volta.