

Nel corso del GTC 2016, l’evento organizzato da Nvidia e durante il quale la società californiana aggiorna gli sviluppatori e la stampa specializzata sulle ultime tecnologie, Jen-Hsun Huang ha annunciato il nuovo Tesla P100. Si tratta dell’acceleratore più avanzato realizzato sino ad oggi da Nvidia e basato sulla nuova Gpu GP100 con architettura Pascal. Come tutti i prodotti della linea Tesla, anche il nuovo P100 è pensato per applicazioni HPC (High Performance Computing), elaborazioni complesse in ambito industriale e scientifico e per fornire la potenza di calcolo richiesta dalle prossime generazioni di data center.
Sebbene questo annuncio sia rivolto al settore enterprise, le informazioni fornite durante la presentazione permettono di conoscere meglio le caratteristiche tecniche di questa architettura che quest’anno debutterà – anche se in forma semplificata – sulla prossima generazione di schede grafiche Nvidia GeForce per il mercato consumer.

Il modulo di calcolo presente nell’acceleratore Tesla P100 e basato sulla Gpu Nvidia GP100.

Il retro del modulo con la Gpu GP100 è stato studiato per essere inserito nei rack dei centri di calcolo in modo semplice e scalabile.
Come è fatta la Gpu Pascal del Tesla P100
L’acceleratore Tesla P100 è costruito attorno alla Gpu GP100 con architettura Pascal che rimpiazzerà progressivamente quella Maxwell 2 dopo poco più di due anni di onorato servizio.
I numeri della Gpu GP100 sono impressionanti. Il die del processore è realizzato negli stabilimenti TSMC (Taiwan Semiconductor Manufacturing Company) con tecnologia FinFET a 16 nanometri con lo scopo di aumentare la densità di transistor per millimetro quadrato, le prestazioni pure e l’efficienza energetica. Sebbene sia realizzato con un processo produttivo che permette di ridurre le dimensioni, il die della Gpu GP100 misura 610 millimetri quadrati per ospitare l’esorbitante numero di 15,3 miliardi di transistor.
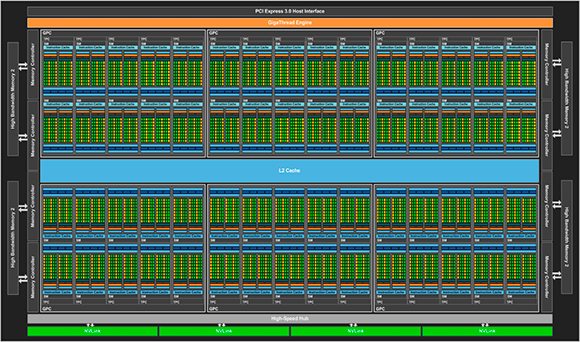
La struttura interna dell’architettura Pascal è organizzata in blocchi GPC all’interno dei quali sono raggruppati i moduli SM.
L’architettura interna è organizzata a blocchi in modo simile a quella delle architetture che l’hanno preceduta, ma anche in questo caso le novità sono molte. L’architettura è organizzata in 6 blocchi GPC (Graphics Processing Cluster), ciascuno dei quali raggruppa al suo interno 10 moduli SM (Streaming Multiprocessor). Ancora, ogni modulo SM contiene al suo interno 64 Cuda Core in singola precisione, 32 Cuda Core in doppia precisione e 4 unità per la gestione delle texture. Nel complesso, l’architettura completa della Gpu GP100 dispone di 3.840 Cuda Core in singola precisione, 1.920 Cura Core in doppia precisione e 240 unità di texture. La nuova architettura punta da un lato sulla forza di calcolo bruta, ma i progettisti hanno ridisegnato le unità SM per ottenere una maggiore efficienza di elaborazione e di consumo rispetto a quella di Maxwell 2.
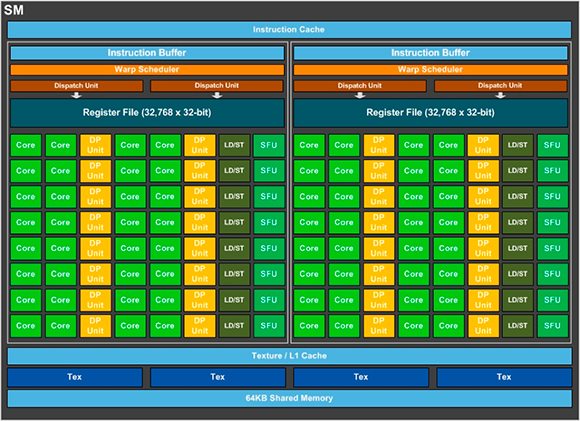
L’architettura dei moduli SM che contengono al loro interno i Cuda Core in singola e doppia precisione, le unità di texture e una cache di primo livello (L1).
La Gpu GP100 presente nell’acceleratore Tesla P100 non utilizza in modo completo l’architettura Pascal, ma 56 moduli SM sui 60 disponibili. Con questi numeri e con una frequenza operativa massima di 1.480 MHz, il Tesla P100 è in grado di fornire una potenza di calcolo di 10,6 TFlops in singola precisione e di 5,3 TFlops in doppia precisione, rispettivamente più del doppio e più del triplo rispetto a quanto offerto dall’acceleratore Tesla K40 basato sull’architettura Kepler.
Per alimentare le proprie unità di calcolo, l’architettura della Gpu GP100 è dotata di 8 controller di memoria a 512 bit – per un totale di 4.096 bit – che servono da canale di comunicazione con la nuova memoria HBM 2 (High Bandwidth Memory).
La tecnologia HBM permette di impilare più chip di memoria – in modo simile ai piani di un grattacielo – per ottenere più spazio di archiviazione a parità di superficie occupata in pianta e permettere anche l’integrazione della memoria sullo stesso package del processore al quale è collegata. La prima generazione di memoria HBM – impiegata da AMD con i processori della serie Fiji – permette di realizzare pile con una capacità massima di 1 Gbyte, mentre la tecnologia di seconda generazione consente di arrivare a 4 Gbyte per ogni pila.
Il Tesla P100 utilizza la tecnologia TSMC Chip-On-Wafer-On-Substrate per assemblare sullo stesso interposero la Gpu GP100 e quattro pile HBM 2 per un totale di 16 Gbyte di memoria. Grazie agli 8 controller di memoria il Tesla P100 può contare su una banda di trasferimento dati massima teorica pari a 720 Gbyte al secondo tra la Gpu e la memoria.
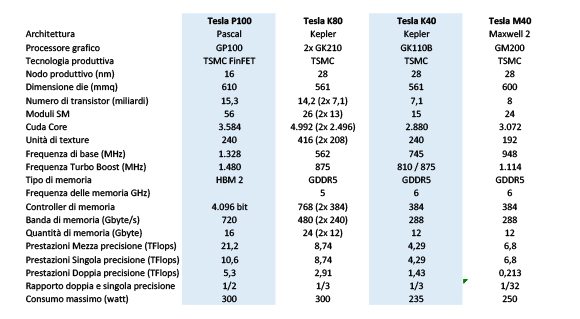
Le caratteristiche tecniche del Tesla P100 a confronto con gli acceleratori di generazione precedente.
Nel corso della presentazione, Nvidia ha confermato anche il supporto alla tecnologia NVLink attraverso la presenza di quattro controller dedicati a questa funzione. La tecnologia NVLink permette di connettere tra loro più Gpu e di supportare il collegamento con le Cpu attraverso un canale capace di una banda di trasmissione dati maggiore a quanto offerto dalla tecnologia Pci Express 3.0. Inoltre, la tecnologia NVLink permetterà elaborazioni con memoria unificata tra le Gpu e offrirà scalabilità delle architetture di calcolo.
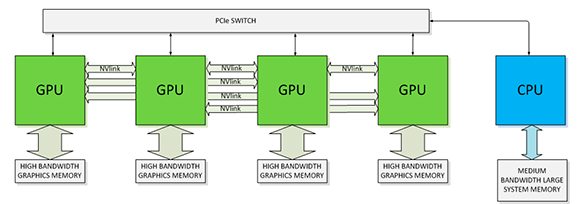
La tecnologia NVLink permette di connettere tra loro più Gpu attraverso un canale dedicato con prestazioni superiori a quelle offerte dal Pci Express 3.0.
Sulla base dei dati e delle caratteristiche annunciate durante il GTC 2016, il nuovo Tesla P100 promette un salto sostanziale nelle prestazioni offerte nei campi in cui troverà spazio l’acceleratore prodotto da Nvidia. A lato di tutto ciò, gli utenti consumer hanno ora un’idea più precisa di cosa aspettarsi dalla prossima generazione di schede grafiche GeForce in arrivo quest’anno.
Se state pensando all’aggiornamento della scheda grafica per il vostro desktop da gioco vi consigliamo di tenere duro e attendere ancora qualche mese perché il 2016 si preannuncia come un anno molto interessante per il settore della grafica. Non assisteremo solo all’arrivo dei visori per la realtà virtuale, ma con Nvidia e Amd che potranno contare su processi produttivi più evoluti dell’ormai obsoleta tecnologia a 28 manometri, la prossima generazione di processori grafici potrebbe essere veramente quella che permetterà fare un salto in avanti sul fronte delle prestazioni.